So What Exactly Is a World Model?
World models seem to be all the rage right now. Every time I go on X, every other post is about a new world model release. Many of the big labs have some version of a World Model. DeepMind, for example, has Genie 3. Meta has V-JEPA 2. World Labs has Marble. Verses AI has Axiom (this last one is interesting because they depart from traditional approaches, I’ll touch on this later).
So what exactly is a world model? How did they come about? How are different people and labs approaching them? And why are they important?
The last few months I’ve been deep in the weeds in generative AI for 3D generation, mostly looking at feed-forward Gaussian Splatting and semantic segmentation (see my previous post if that’s your thing). I started following a lot of people on X who are pushing what is possible in this space, and as a result started getting a lot of content on world models. So I did what I always do when something catches my interest. I dove deep into the papers and tried to understand the current landscape: what we mean when we talk about “world models”, what different approaches are being tried, what seems to work, and where we are likely to see progress.
The simple definition
A world model is a system that learns an internal representation of an environment and can predict how that environment will change given some set of actions or conditions.
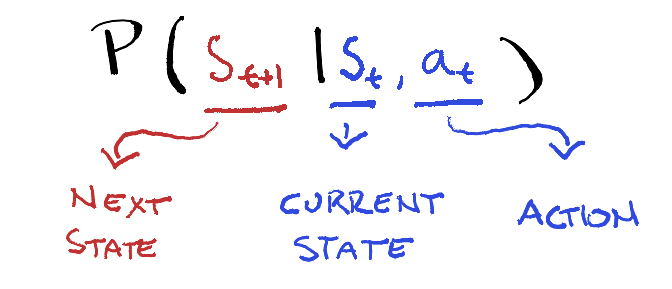
That is the core idea. The system builds a model of its world, then uses that model to run “what if” scenarios, simulating possible futures before deciding what to do.
Our own brains build a world model to be able to function in the world. As Max Bennett succinctly puts it in his book “A Brief History of Intelligence” our neocortex evolved to actively predict what’s happening and update those predictions with incoming signals.
To understand why this is necessary let’s look only at visual information for a moment. Raw sensory signals take time to travel and be processed by our brain. For the visual cortex the time it takes is in the order of ~100ms. This means that the “raw feed” our brains are getting is always slightly in the past. If we were to act on this information it would be nearly impossible to act/react to the world efficiently. Our brain compensates for this by simulating slightly ahead of the present. Essentially, our conscious experience is a rendered prediction of the current moment.
This feature of the brain also lets us plan/simulate possible futures. Even when we try not to, our minds are constantly playing out scenarios (the ones we don’t like we usually call intrusive thoughts).
The difference is that we are trying to get machines to do this from data, at scale, with enough fidelity and reliability to be useful.
To be more precise: a world model is a learned function \(f\) that takes a state \(s_t\) and an action \(a_t\) and predicts the next state \(s_{t+1} = f(s_t, a_t)\). Where current approaches diverge is mostly in what they consider a “state” to be. For some it is raw pixels. For others it is a latent vector, or a set of 3D Gaussians, or a probability distribution. The prediction mechanism varies too: autoregressive, diffusion-based, Bayesian. And then there is the question of whether you can actually see the output or whether it lives entirely in some compressed internal space.
We Already Have Rudimentary World Models
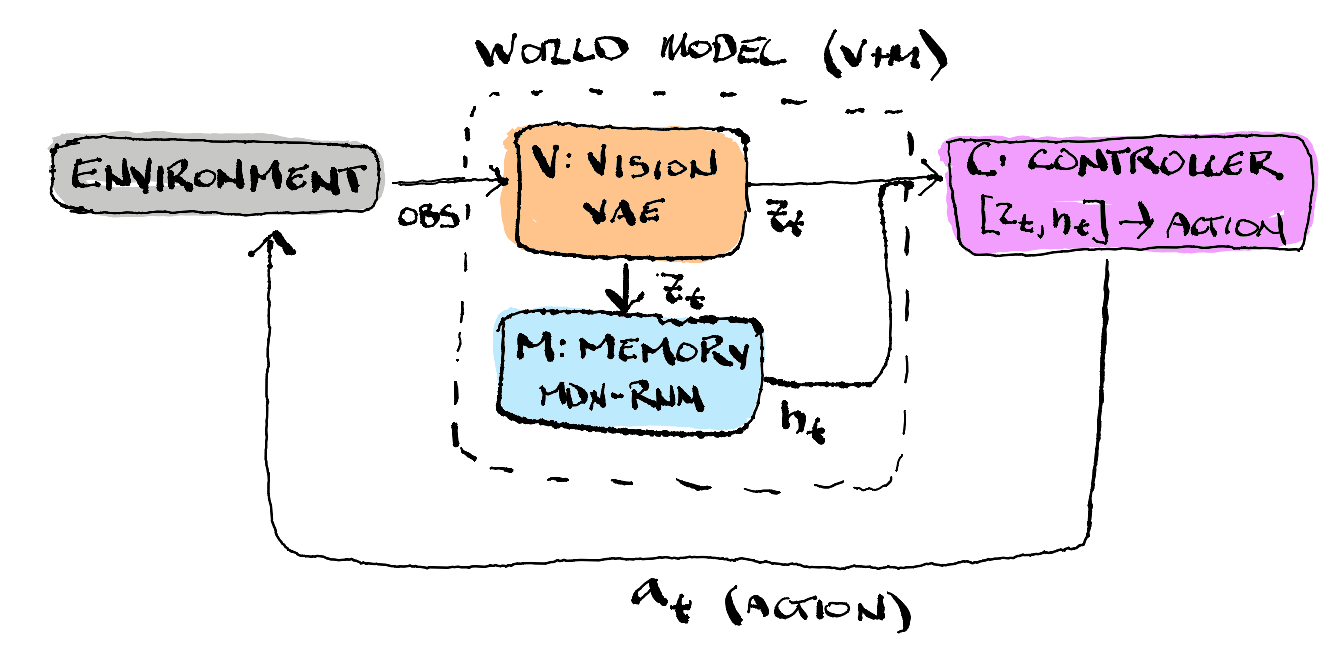
World models are not exactly new. In 1990, in a paper titled Making the World Differentiable, Jürgen Schmidhuber proposed training a recurrent neural network to act as a differentiable model of the environment (essentially a world model). A separate controller network can then plan ahead by doing gradient descent through this world model, rather than reacting directly to inputs. In 2018 these ideas were finally able to come to fruition. In the 2018 World Models paper by David Ha and Jürgen Schmidhuber, they were able to bring the 1990 ideas to life. The world model is trained in an unsupervised manner to learn a compressed spatial and temporal representation of the environment. By using features extracted from the world model as inputs to an agent, a very compact and simple policy can be used to solve downstream tasks.
We also already see glimpses of “world model” in large language models. We train a very large transformer model to predict the next token given some previous text, and in the process the model seems to build some internal representation of the world.
Here is an extract from Ilya Sutskever in a Fireside chat with Jensen Huang at NVIDIA’s GTC conference in 2023 - where he makes the point very clearly.
“when we train a large neural network to accurately predict the next word in lots of different texts from the internet, what we are doing is that we are learning a world model. It looks like we are learning that it may look on the surface, that we are just learning statistical correlations in text. But it turns out that to just learn the statistical correlations in text to compress them really well. What the neural network learns is some representation of the process that produced the text. This text is actually a projection of the world.”
We are only starting to scratch the surface of our understanding here, but mechanistic interpretability is uncovering interesting structure: these models appear to hold spatial, temporal, and causal knowledge just through the process of next-token prediction. (I am oversimplifying, and not taking into account all the post-training work using reinforcement learning, chain-of-thought reasoning, and all the state-of-the-art tricks in LLM training. My point is that LLMs are already a very rudimentary world model.)
So what do LLMs lack? For one, they operate in language space, not in the physical world. They can describe a physical scene, but they have no grounded understanding of gravity, mass, or friction. They hallucinate confidently about spatial relationships and have no internal mechanism for simulating state transitions. When embedded in an agentic scaffolding, they can act in and observe an environment, but they cannot simulate the environment and run counterfactuals.
Yann LeCun has been one of the most vocal critics on this point. His argument, broadly, is that autoregressive token prediction is fundamentally the wrong paradigm for building systems that understand the physical world. The problem is that too much capacity gets spent modelling the surface form of language rather than the underlying structure of physical reality. He left Meta in late 2025 and founded AMI Labs, an independent startup that raised over $1 billion, to pursue his own approach.
Two Types, One Name
Before we get into how different people are approaching the problem, it is worth noting that the field uses “world model” for two fundamentally different things:
Latent space models forecast what happens next from history and actions. Meta’s V-JEPA 2 is the clearest example. It predicts in latent space and gets state-of-the-art results on visual understanding and zero-shot robot control. However, it cannot produce anything you can look at (think image, video, or 3D mesh). It has clearly learned something about how the world works, but cannot render that world itself.
Generative models go the other direction: they synthesize scenes you can actually see. Google’s Genie 3 gives you a navigable 3D world. Cosmos generates video where the 3D structure is consistent enough that you can recover camera poses from the output about 62.6% of the time.
An interesting recent finding is that this dichotomy may be dissolving. Var-JEPA showed that predictive and generative approaches can be unified under probabilistic theory. The divide is less fundamental than previously thought. It is more of a choice along a spectrum of how much information the model is asked to reconstruct.
Let’s imagine two ways to learn about a room. A generative model learns to render the room with crazy levels of detail. It does so because it has been trained to reproduce everything and penalized when it gets something wrong. A latent space model (like JEPA) on the other hand, learns to recognize the room. It builds an internal compressed representation of the room and can tell you if two photos are of the same room. It cannot draw the room itself. The question is: are these fundamentally different skills, or different levels of the same skill?
Var-JEPA showed they are the same skill at different levels. The “internal summary” that JEPA builds turns out to closely mirror something called a variational posterior, a compressed probabilistic description of the data. And JEPA’s predictor, which forecasts one summary from another, closely mirrors a learned conditional prior, a model of what summaries are likely given what you have already seen.
If you see the connection to Variational Auto Encoders, it’s because the posterior and the predictor are exactly the inference and generative components of a coupled latent-variable model. Once you add decoders to reconstruct the original observations, you get a complete ELBO.
The Architectural Choices
Every world model makes different architectural decisions that determine what it can and cannot do.
State representation:
Deciding on the state representation is one of the most important choices as it determines what information makes it through compression and defines what can be extracted from the model.
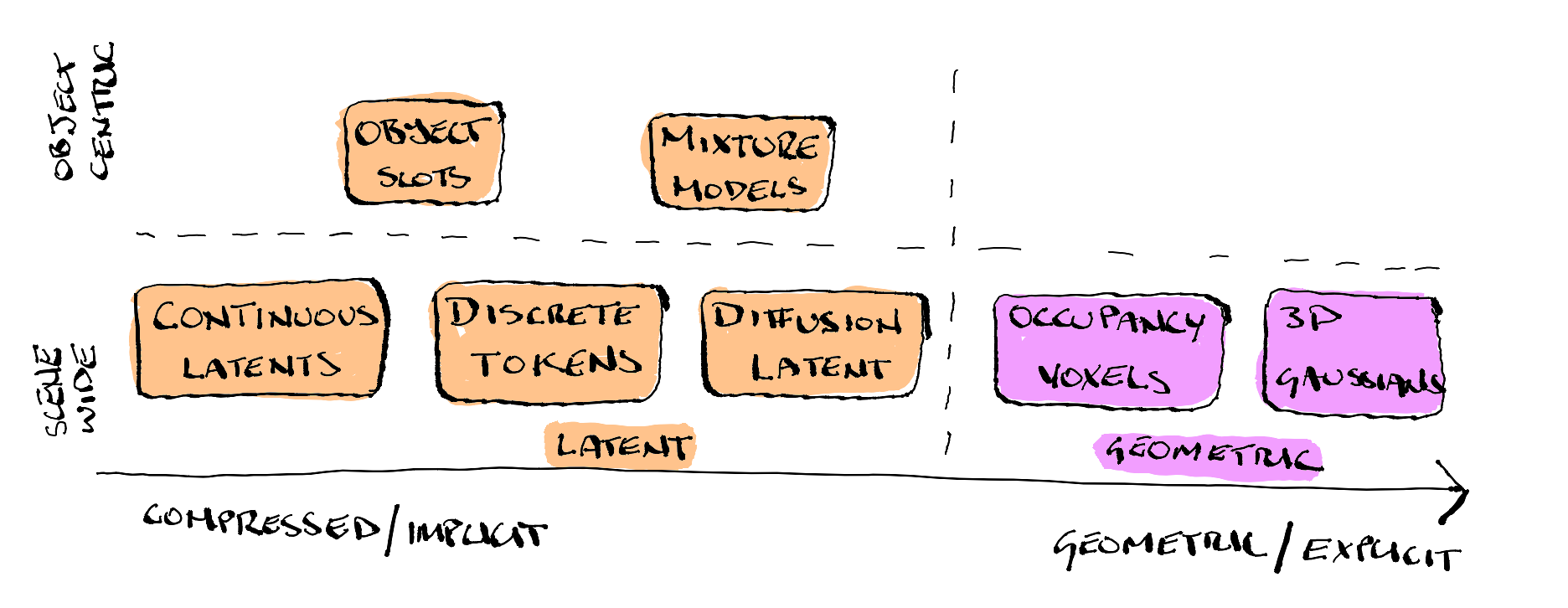
The majority of world models compress scenes into a compact latent representation, TD-MPC2 and JEPA use continuous latent vectors, while DreamerV3 uses discrete categorical latents (32 one-hot vectors sampled from 32 categorical distributions). All three work this way. Geometry is implicit at best, and 3D information is not directly extractable. Similarly, Discrete tokenization via Vector Quantised-Variational Auto Encoders (VQ-VAE), is used by GAIA-1, IRIS, Genie 2, and Genie 3. Quantization is fast and scalable but actively discards spatial detail, making geometry recovery even harder. Diffusion-based continuous latents used in (Cosmos, GAIA-2, DIAMOND) do better, they preserve more 3D structure than discrete tokens, and it has been shown that camera poses can be recovered from this approach.
Object-centric slot representations (SlotFormer, SOLD, DINOSAUR) also use latent representations, but take a different approach by decomposing a scene into a fixed set of structured vectors. Most world models encode an entire scene into a single representation (one latent vector, token sequence, voxel grid, etc.). Object-centric models decompose a scene into a fixed set of slots, where each slot is a separate vector (typically 64-256 dimensions). Think of it like giving the model a tray of empty cups and asking it to sort the scene’s contents, one object per cup. The model learns to do this without labels, purely through a competitive attention mechanism where slots fight over image patches. They capture appearance and motion well, but not geometry: a slot can tell you “there is a red car moving left” but not “the car is 4.2 meters long and 12 meters away.”
At the other end of the spectrum sit representations that make geometry a first-class citizen. Occupancy voxel models (OccWorld, OccSora, SparseWorld) recover it at voxel resolution by construction. 3D Gaussian models (GaussianDWM, Street Gaussians) go further, representing geometry explicitly and continuously.
AXIOM’s mixture model components are somewhere in between, they capture object-level structure, but geometric fidelity is untested. What is interesting about AXIOM (Active eXpanding Inference with Object-centric Models) is that is goes againsts the dominant paridigm and does away with neural networks and gradient-based optimization. Instead, it updates sequentially one frame at a time using variational Bayesian inference, which means it can learn from a single event rather than needing to see thousands of samples. The generative model is expanded online by growing and learning mixture models from single events, then periodically refined through Bayesian model reduction to induce generalisation. The authors show good performance on 2D game environments, whether it can scale to real-world 3D scenes is an open question.
Prediction mechanism:
Once the state representation has been decided, the next choice is how to evolve that state forward in time. The dominant approach has historically been autoregressive prediction. The model generates the next token (frame, occupancy state, etc) one step at a time, just like a LLM. GAIA-1, IRIS, OccWorld, and SlotFormer all work this way. This approach scales well but errors compound. Since each predicted step is fed back as input for the next, small mistakes can snowball over long rollouts.
Diffusion-based prediction addresses this by framing future states as a denoising problem rather than a sequential generation problem. Cosmos, DIAMOND, OccSora, and GAIA-2 all take this route. Because generation is iterative rather than sequential, the model can refine its prediction globally rather than token by token. Because of this, the resulting outputs preserve significantly more spatial detail. However, this increased fidelity is not free, and results in much higher compute cost as each prediction requires multiple denoising steps rather than a single forward pass.
Another approach is to maintain a compact latent state and update it with a learned transition function (typically a Recurrent State Space Model (RSSM)). DreamerV3 and SOLD take this approach. It makes single-step prediction much faster but suffers from the same error compounding effect as next-token prediction. The latent state can drift and long-horizon rollouts become unreliable.
Then there is Latent Space Model Predictive Control, which sits at the intersection of latent dynamics and online planning. Instead of relying solely on a fixed policy or a purely autoregressive rollout to decide the next move, these architectures optimize trajectories at test time. They use a learned world model to simulate potential futures in a latent space, but the actual action selection is performed by Model Predictive Path Integral (MPPI) control, which replans at every decision point. Basically you can think of it as simulating many possible future scenarios using its learned model of how the world works before picking the best path. This allows compute to be scaled up at inference. More samples typically lead to better plans, though it requires a fresh optimization pass for every action.
Taking a very different approach again, AXIOM treats control and state evolution as a recursive inference problem. Rather than using backpropagation to update its world model during interaction, it updates a mixture model to maintain principled uncertainty estimates. This allows the model to “know what it doesn’t know,” providing a mathematical safety net that standard neural transition functions lack.
Action conditioning:
Some world models are passive observers, for example, they predict what happens next in a video stream. Others are action-conditioned, they predict what happens given a specific action. This distinction is important for 3D reconstruction, because action conditioning is what you need for view planning, essentially being able to ask “if I move the camera here, what will I see?”
The nature of those actions varies widely. At one end sit RL-native models like DreamerV3 and SOLD, which condition on explicit control signals (discrete or continuous actions concatenated directly with the latent state). They were designed for agents acting in simulated environments. GAIA-1 occupies a middle ground, conditioning on tokenized driving actions (speed and steering) which are physical but still domain-specific to autonomous vehicles. OccSora replaces action tokens with trajectory prompts fed into a diffusion transformer, giving it a more continuous and geometric flavour.
Genie 3 takes an unusual position, it learns its action space from video rather than having one specified. A latent action model infers what “actions” must have occurred between frames, producing a representation that generalises surprisingly well but that can’t be directly steered with human-interpretable commands. AXIOM approaches action differently again, through active inference. Actions are chosen to reduce uncertainty under a free energy objective, which means the model is always asking “what observation would teach me the most?” rather than “what observation do I expect?”
For reconstruction specifically, the models that matter most are those that accept camera pose as a first-class action type. Cosmos supports multi-view camera control alongside text prompts, making it possible to query the model for a specific viewpoint directly. For 3D reconstruction, a world model that accepts camera poses as actions can serve as a learned scene prior: given a sparse set of real observations, it can hallucinate what the scene would look like from unobserved viewpoints. Whether the geometry underlying those hallucinations is consistent enough to be useful is a different question, and one that seems to remain open.
Why Does Any of This Matter?
A few reasons.
Robotics and embodied AI. If you want a robot that does not break things, it helps if it can imagine what will happen before it moves. That is what world models enable.
Grounding language models. LLMs hallucinate about the physical world because they have never interacted with it. World models are one way to give them that grounding.
3D reconstruction and urban modelling. This is where my own interest sits. I spent a good part of my life in the spatio-temporal world. A mix of quantitative geography, urban science, earth observation, spatio-temporal statistics and ML. I can see a lot of ideas that have emerged in those domains playing an important role here. Spatial autocorrelation for example could be used as prior for scene consistency, spatio-temporal point processes could be applied for modelling dynamic urban elements, uncertainty quantification methods from geostatistics could be applied to novel view confidence. The flow of ideas between these fields feels like it is just getting started.
Where This Is Heading
World models and 3D reconstruction are seem to be arriving at similar things. The new “4D World Models: Bridging Generation and Reconstruction” workshop joins USM3D’s traditional focus on structured urban reconstruction, and both communities are increasingly talking to each other.
Five trends I am watching:
1. Generated frames as reconstruction input. Cosmos’s 62.6% pose recovery rate means generated video has enough structure to potentially augment sparse SfM captures. If this works, world models could become a data source for reconstruction, not just a consumer of reconstructed scenes.
2. The representation spectrum. JEPA (latent, no output) to DreamerV3 (latent, imagination only) to object-centric slots (per-object latent, no geometry) to Genie (pixels, no geometry) to tokenized autoregressive (discrete tokens, lossy) to Cosmos (pixels with 3D structure) to OccWorld (discrete 3D voxels) to GaussianDWM (explicit 3DGS) to reconstruction (full geometry). They are all points on a continuum, and the boundaries are becoming porous. Dreamer-CDP imports JEPA into RL. SOLD imports slots into imagination-based RL. Cosmos-NuRec bridges generation and reconstruction. The interesting work in the next year will probably happen at the boundaries.
3. Occupancy as a bridge representation. The occupancy paradigm evolved faster than any other in 2024-2025. From OccWorld’s autoregressive baseline to SparseWorld’s real-time sparse queries in under two years. Drive-OccWorld already showed you can create a perception-to-planning loop. The open question is whether any of this transfers beyond driving.
4. The decoder-free convergence. Across three independent lineages: JEPA (never had a decoder), Dreamer (removed it: R2-Dreamer, NE-Dreamer), and object-centric (replaced pixel targets with DINO features: DINOSAUR), the field seems to be arriving at the same insight: pixel-level reconstruction wastes capacity on task-irrelevant details. This matters for 3D because the question becomes: does removing reconstruction lose geometric information, or does it actually free the model to learn spatial structure better?
5. Compositional vs monolithic latent dynamics. SOLD outperforms DreamerV3 on relational tasks. AXIOM beats it with ~400x fewer parameters. The question is whether slot-based decomposition can handle real world geometric complexity, or whether AXIOM’s mixture model approach, which naturally adapts its slot count, is the better fit.